Lecture 8: Address Translation
Want Processes to Co-exist
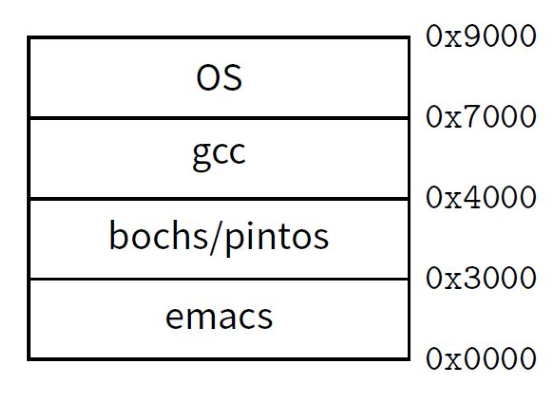
- Consider multiprogramming on physical memory
- What happens when pintos needs to expand?
- If emacs needs more memory than is on the machine?
- If pintos has an error and writes to address 0x7100?
- When does gcc have to know it will run at 0x4000?
- What if emacs is not using its memory?
Virtualizing Resources
- Physical Reality: different processes/threads share the same hardware
- Need to multiplex CPU (done)
- Need to multiplex use of Memory (today)
- Need to multiplex disk and devices (later in term)
- Why worry about memory sharing?
- The complete working state of a process is defined by its data in memory (and registers)
- Consequently, two different processes cannot use the same memory
- Two different data cannot occupy same locations in memory
- May not want different threads to have access to each other’s memory
Next Objective
- Dive deeper into the concepts and mechanisms of memory sharing and address translation
- Enabler of many key aspects of operating systems
- Protection
- Multi-programming
- Isolation
- Memory resource management
- I/O efficiency
- Sharing
- Inter-process communication
- Demand paging
- Today: Linking, Segmentation
Recall: Single and Multithreaded Processes
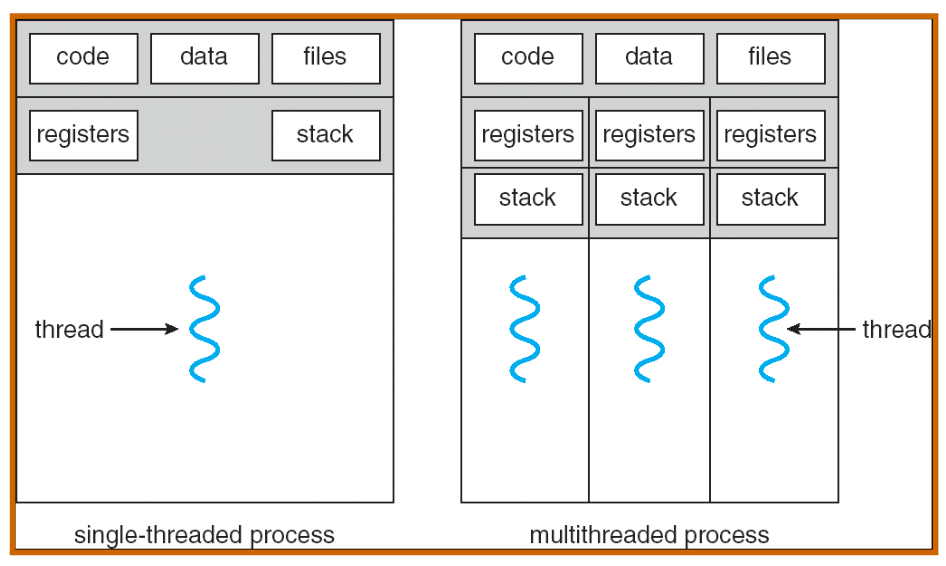
- Threads encapsulate concurrency
- “Active” component of a process
- Address spaces encapsulate protection
- Keeps buggy program from trashing the system
- “Passive” component of a process
Important Aspects of Memory Multiplexing
- Protection: prevent access to private memory of other processes
- Kernel data protected from User programs
- Programs protected from themselves
- May want to give special behavior to different memory regions (Read Only, Invisible to user programs, etc)
- Controlled overlap: sometimes we want to share memory across processes.
- E.g., communication across processes, share code
- Need to control such overlap
- Translation:
- Ability to translate accesses from one address space (virtual) to a different one (physical)
- When translation exists, processor uses virtual addresses, physical memory uses physical addresses
- Side effects:
- Can be used to give uniform view of memory to programs
- Can be used to provide protection (e.g., avoid overlap)
- Can be used to control overlap
Recall: OS Bottom Line: Run Programs
Recall: Address Space
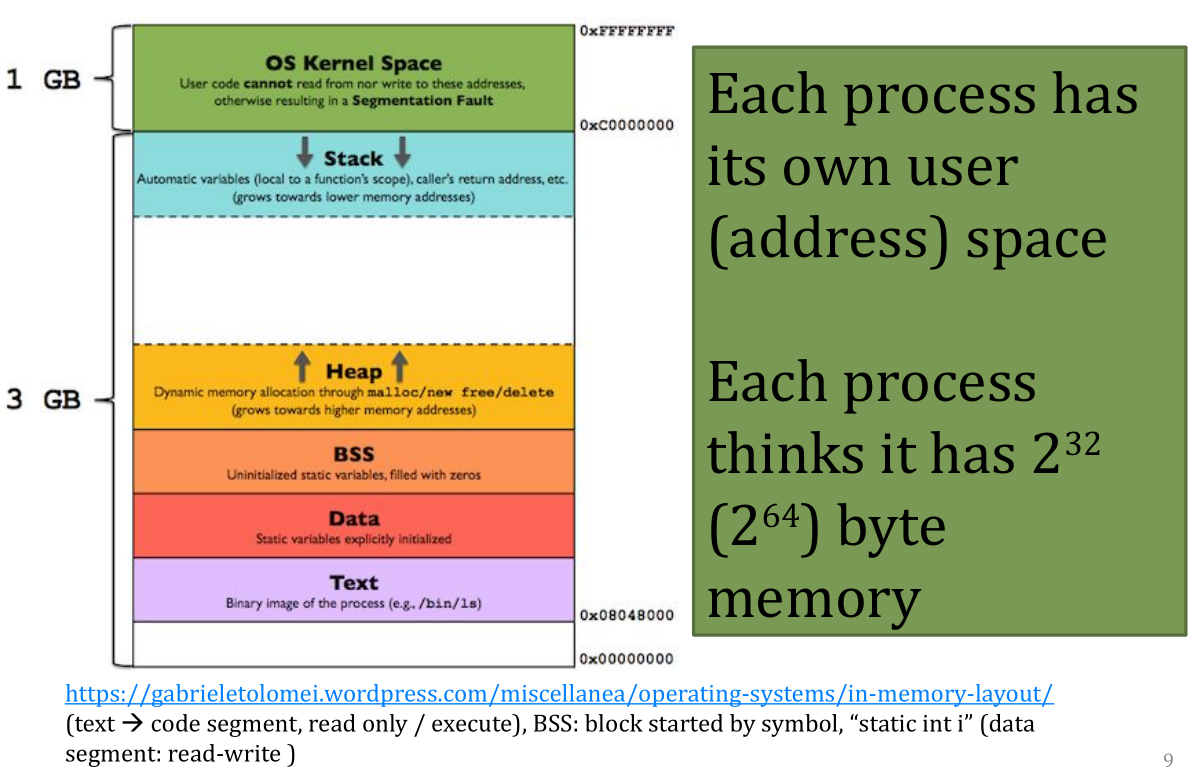
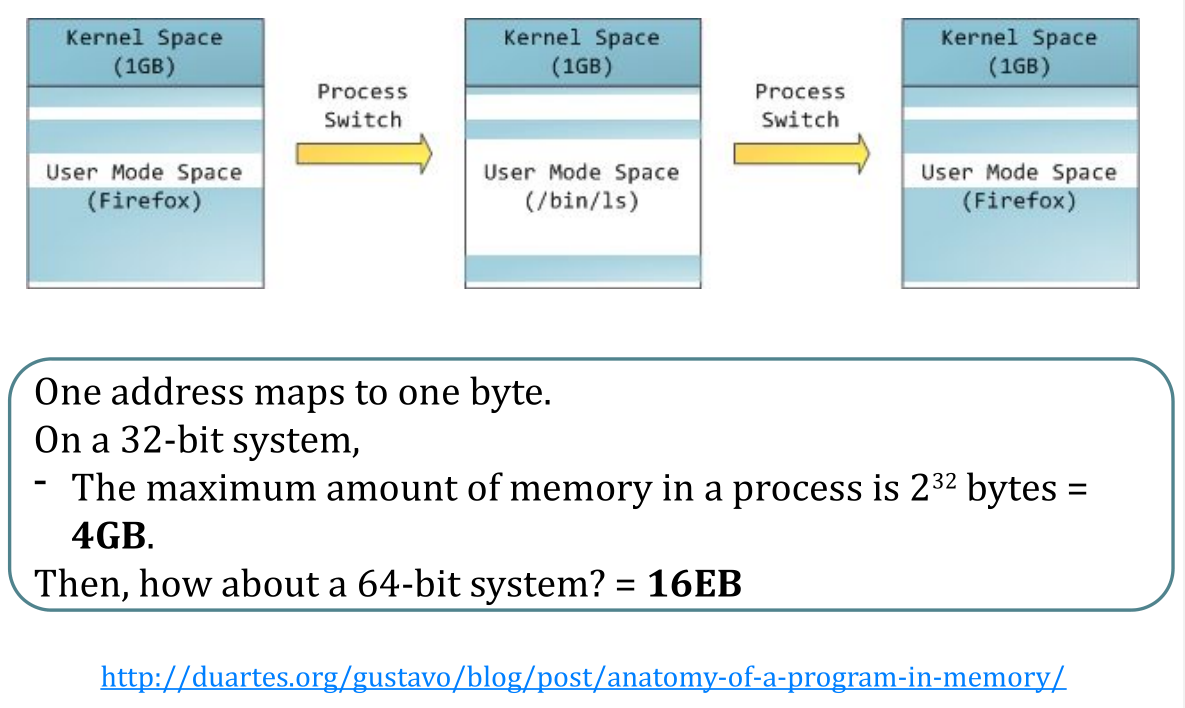
Recall: Context Switch
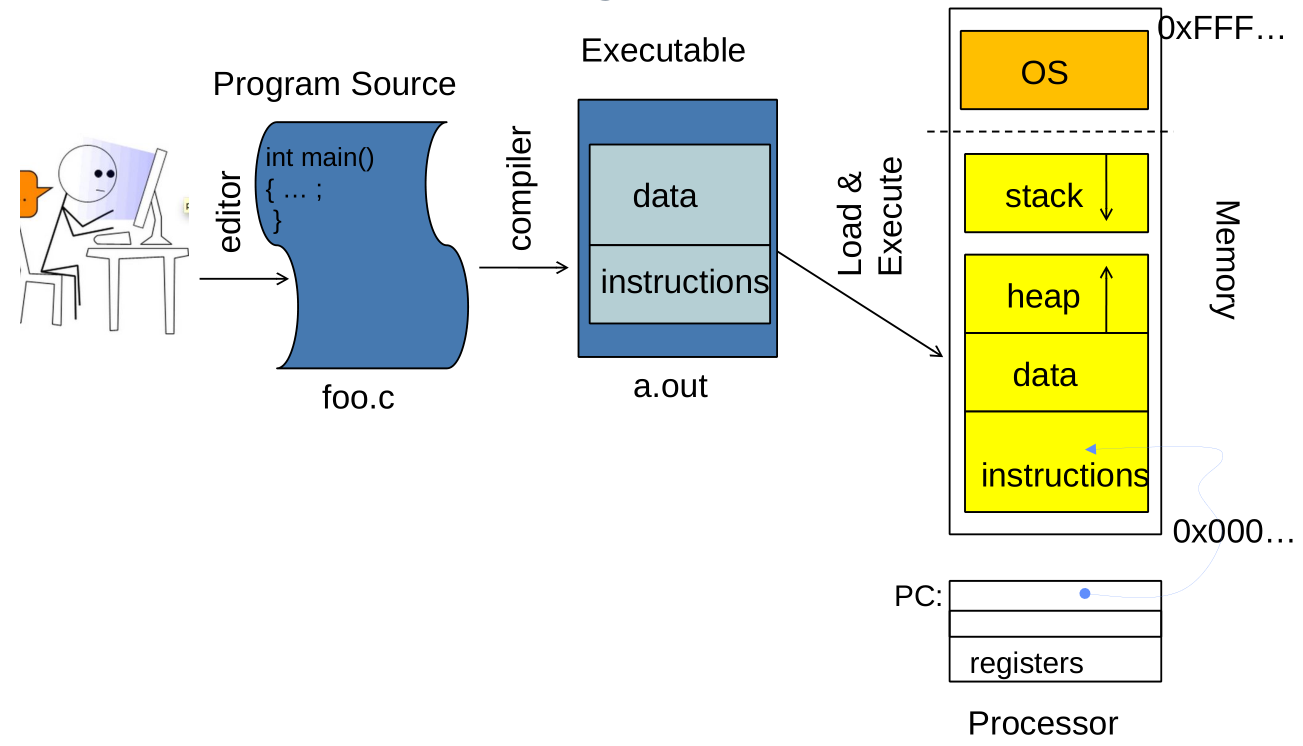
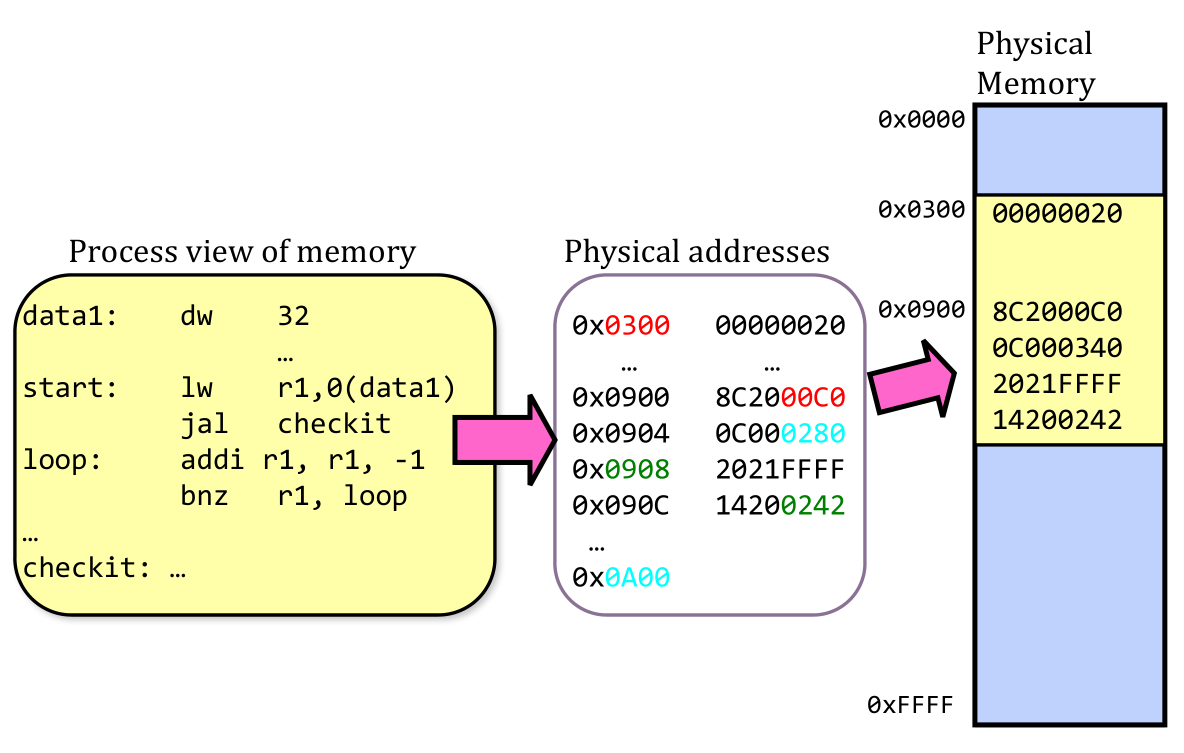
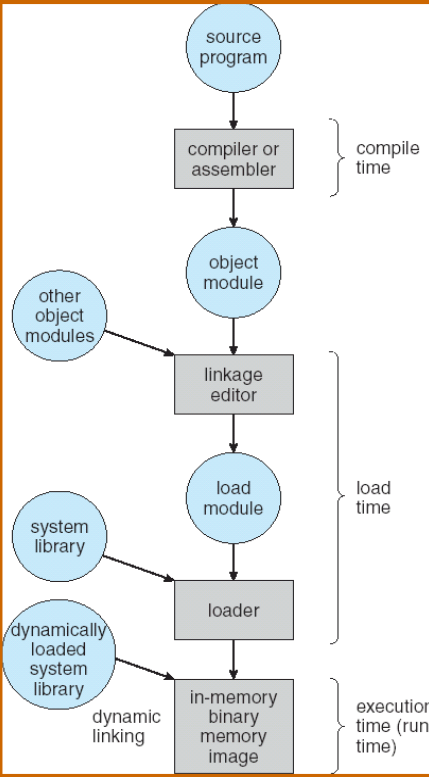
Binding of Instructions and Data to Memory
2nd copy of program from previous example
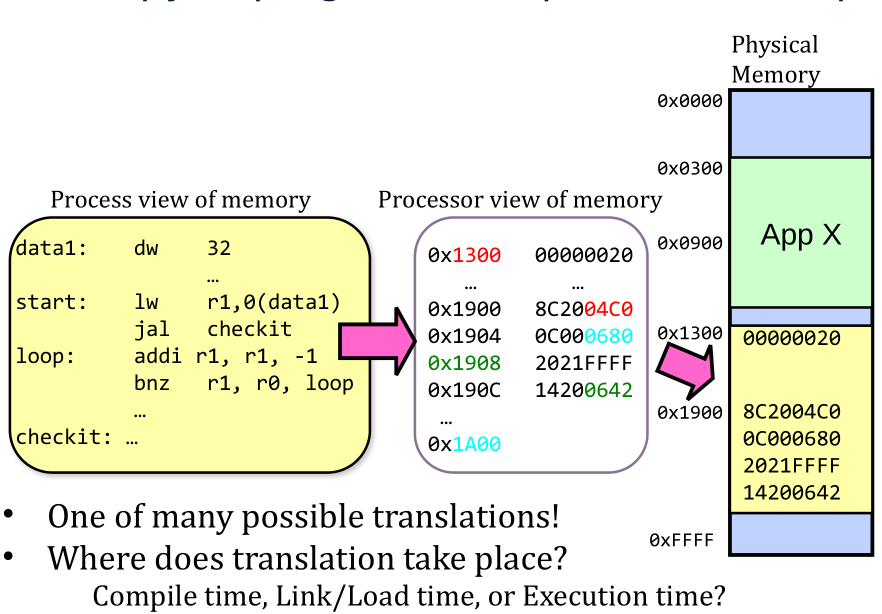
Multi-step Processing of a Program for Execution
- Preparation of a program for execution involves components at:
- Compile time (i.e., “gcc”)
- Link time (UNIX “ld” does link)
- Load time
- Execution time (e.g., dynamic libs)
- Addresses can be bound to final values anywhere in this path
- Depends on hardware support
- Also depends on operating system
- Dynamic Libraries
- Linking postponed until execution
- Small piece of code, stub, used to locate appropriate memory-resident library routine
- Stub replaces itself with the address of the routine, and executes routine
Multiplexing Memory Approaches
- Uniprogramming
- Multiprogramming
- Without protection
- With protection (base+bound)
- Virtual memory
- Base & Bound
- Segmentation
- Paging
- Paging + Segmentation
Uniprogramming
Uniprogramming (no Translation or Protection)
- Application always runs at same place in physical memory since only one application at a time
- Application can access any physical address
Multiprogramming (primitive stage)
Multiprogramming without Translation or Protection
- Must somehow prevent address overlap between threads
Use Loader/Linker: Adjust addresses while program loaded into memory (loads, stores, jumps)
- Everything adjusted to memory location of program
- Translation done by a linker-loader (relocation)
- Common in early days (… till Windows 3.x, 95?)j
With this solution, no protection: bugs in any program can cause other programs to crash or even the OS
Multiprogramming (Version with Protection)
- Can we protect programs from each other without translation?
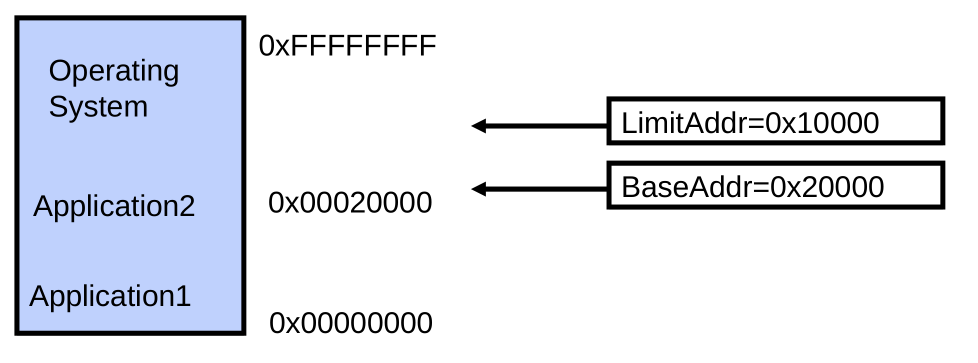
- Yes: use two special registers BaseAddr and LimitAddr to prevent user from straying outside designated area
- If user tries to access an illegal address, cause an error
- During switch, kernel loads new base/limit from PCB (Process Control Block)
- User not allowed to change base/limit registers
Virtual memory support in modern CPUs
- The MMU – memory management unit
- Usually on-chip (but some architecture may off-chip or no hardware MMU)
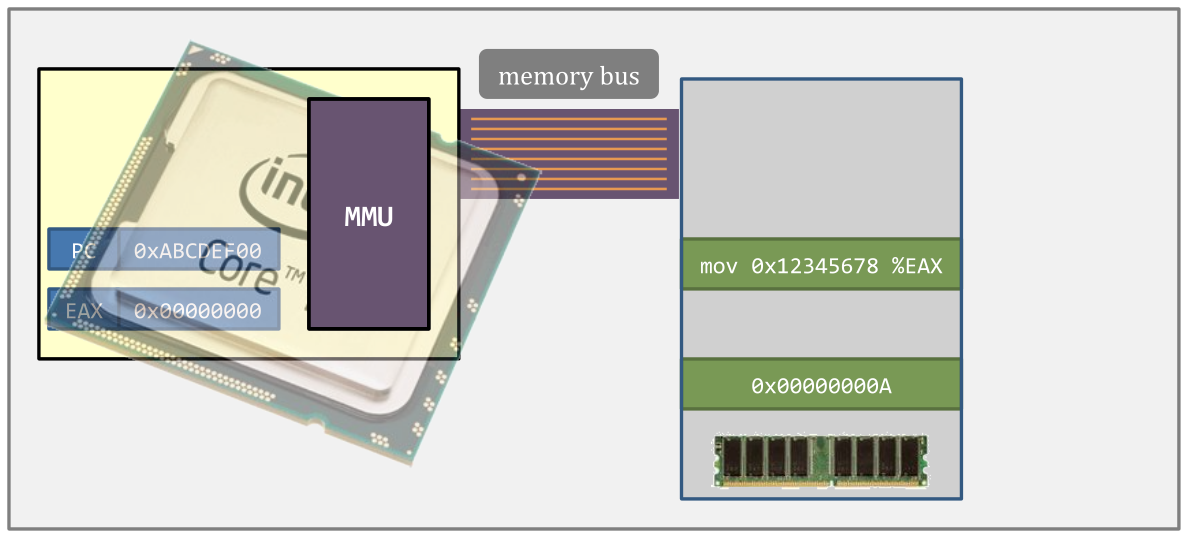
Virtual memory – how does it work?
- Step 1. When CPU wants to fetch an instruction
- the virtual address is sent to MMU and
- is translated into a physical address.
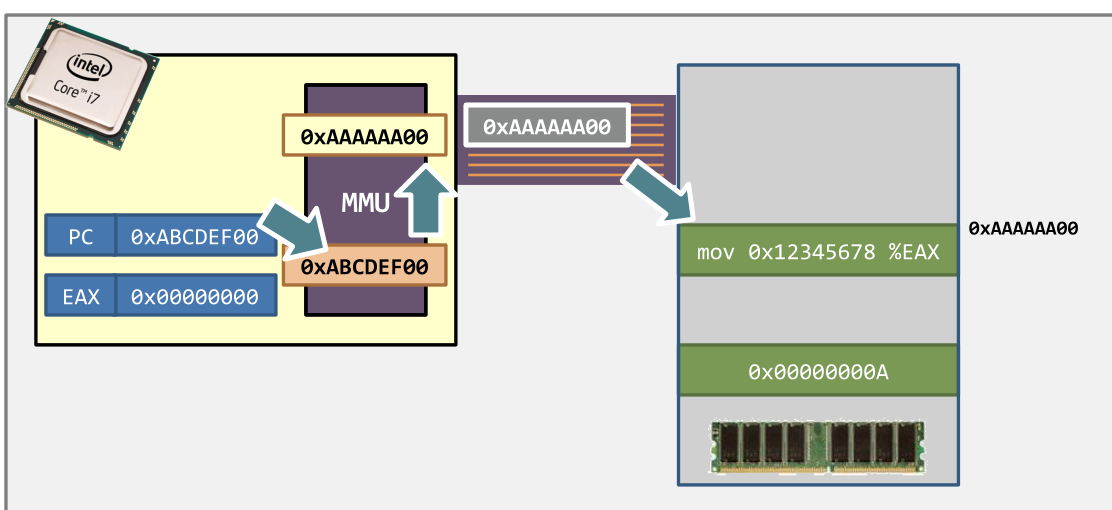
- Step 2. The memory returns the instruction
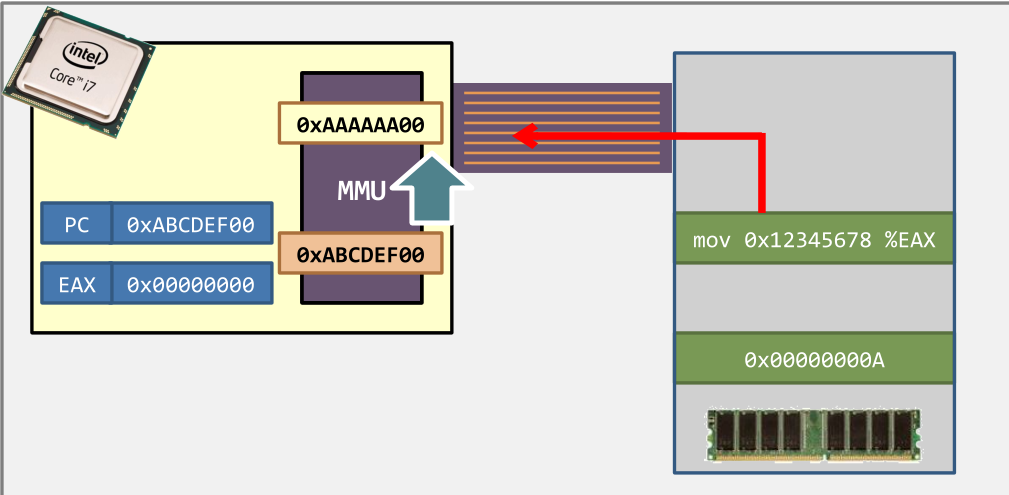
- Step 3. The CPU decodes the instruction.
- An instruction uses virtual addresses
- but not physical addresses.
- An instruction uses virtual addresses
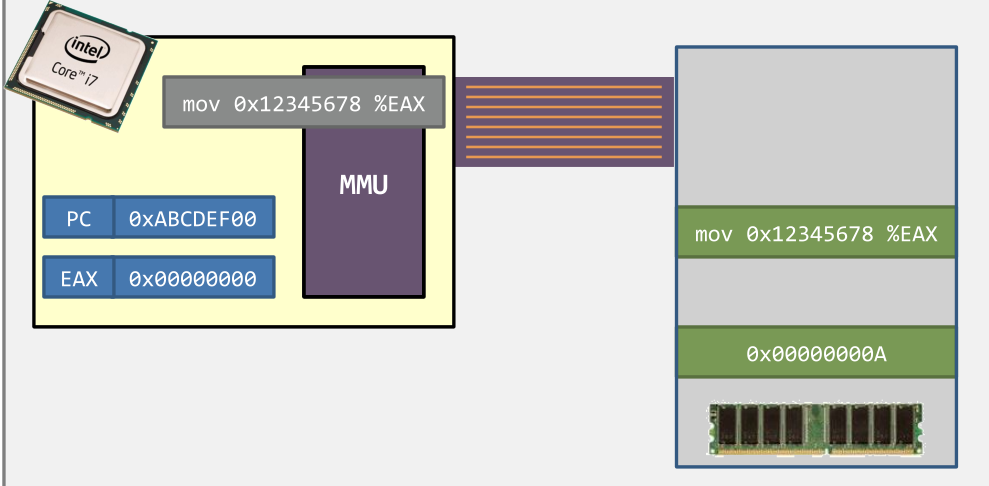
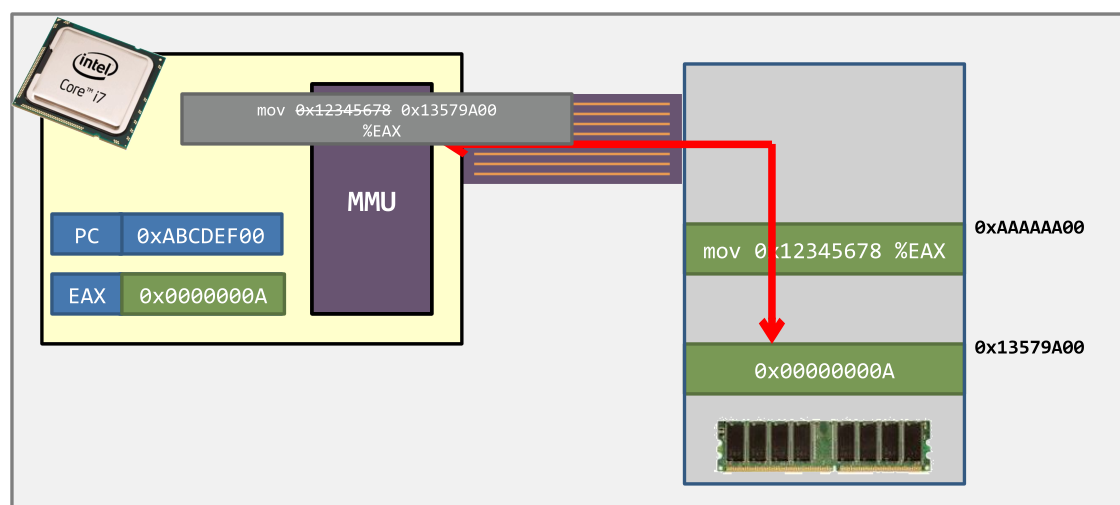
- Step 4. With the help of the MMU, the target memory is retrieved.
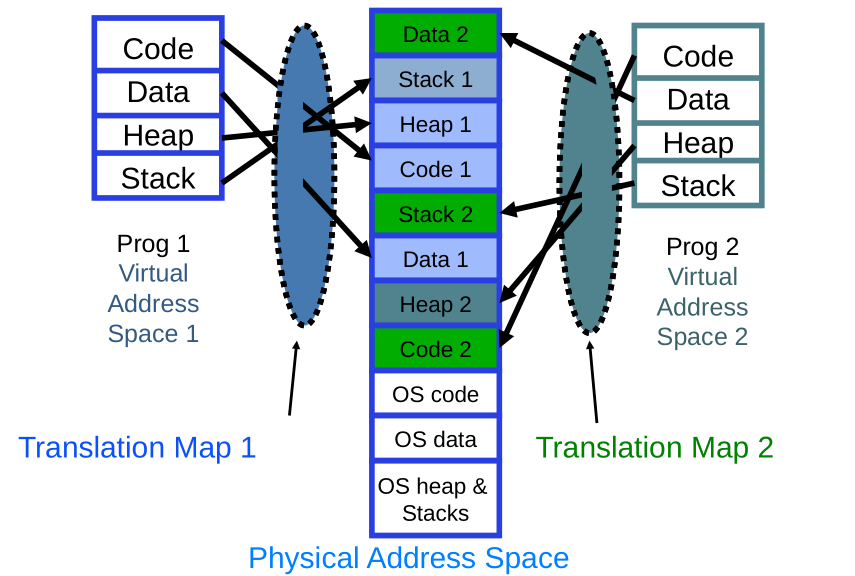
General Address translation
- Recall: Address Space:
- All the addresses and state a process can touch
- Each process has different address space
- Consequently, two views of memory:
- View from the CPU (what program sees, virtual memory)
- View from memory (physical memory)
- Translation box (MMU) converts between the two views
- Translation makes it much easier to implement protection
- If task A cannot even gain access to task B’s data, no way for A to adversely affect B
- With translation, every program can be linked/loaded into same region of user address space
Simple Example: Base and Bounds
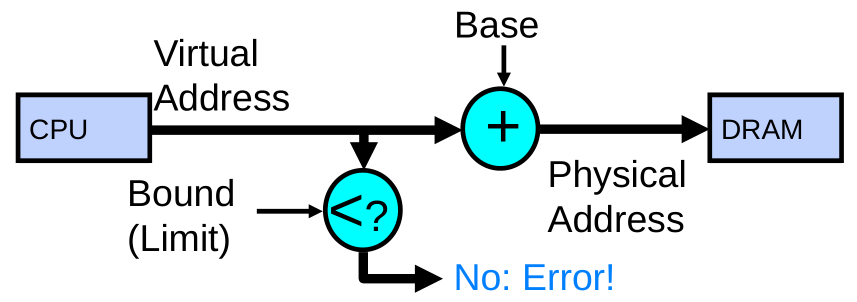
- Could use base/bounds for dynamic address translation – translation happens at execution:
- Alter address of every load/store by adding “base”
- Generate error if address bigger than limit
- This gives program the illusion that it is running on its own dedicated machine, with memory starting at 0
- Program gets continuous region of memory
- Addresses within program do not have to be relocated when program placed in different region of DRAM
Issues with Simple B&B Method
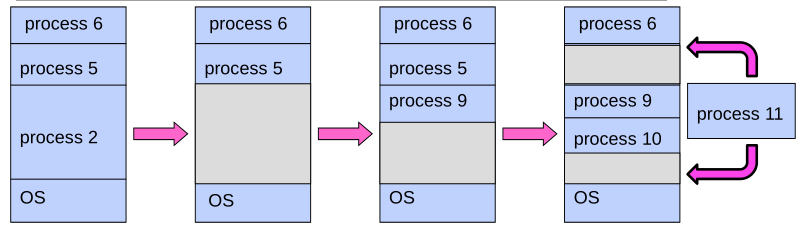
- Fragmentation problem over time
- Not every process is same size memory becomes fragmented
- Missing support for sparse address space
- Would like to have multiple chunks/program (Code, Data, Stack)
- Hard to do inter-process sharing
- Want to share code segments when possible
- Want to share memory between processes
- Helped by providing multiple segments per process
More Flexible Segmentation
- Logical View: multiple separate segments
- Typical: Code, Data, Stack
- Others: memory sharing, etc
- Each segment is given region of contiguous memory
- Has a base and limit
- Can reside anywhere in physical memory
Implementation of Multi-Segment Model
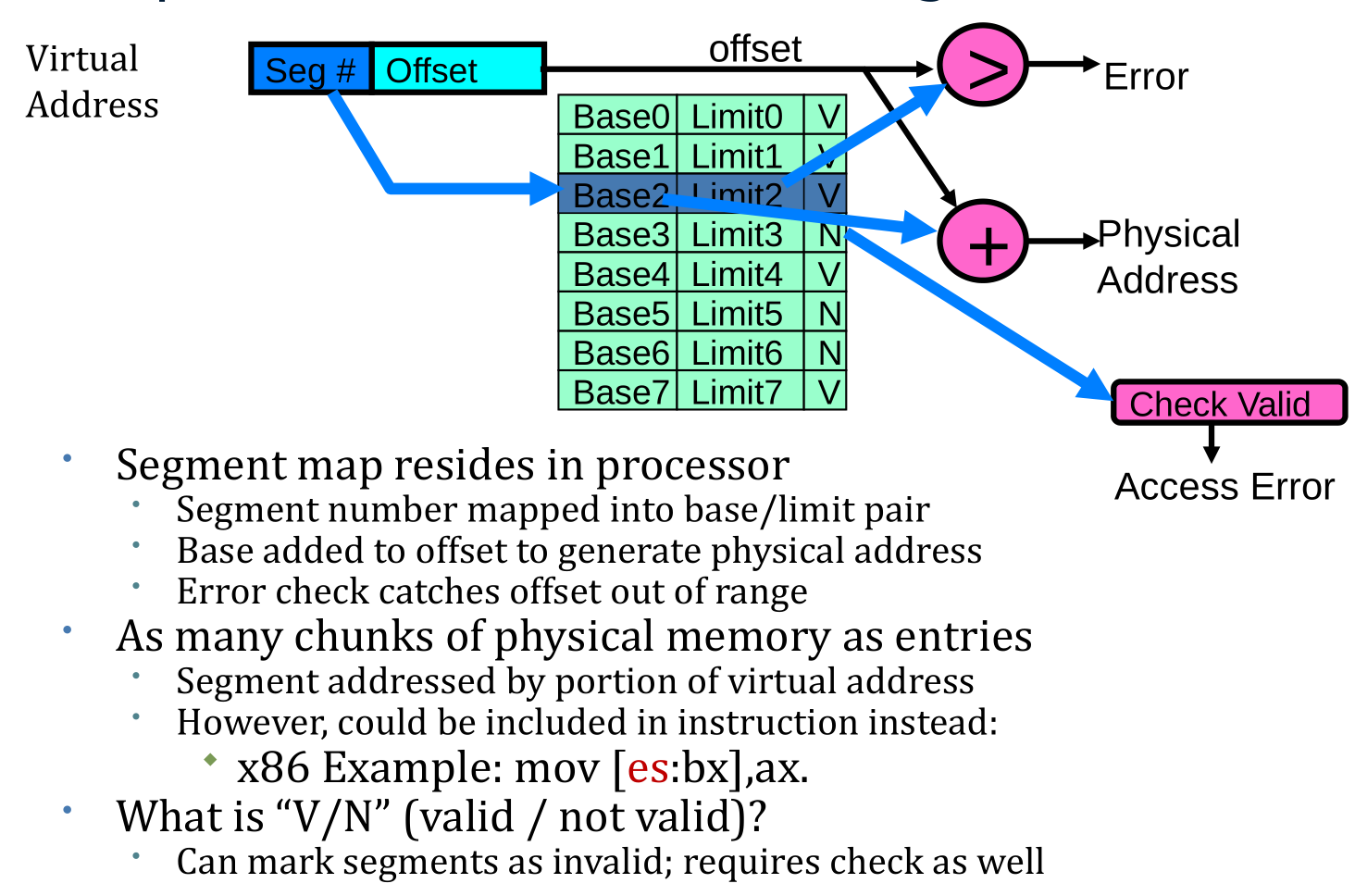
Observations about Segmentation
- Virtual address space has holes
- Segmentation efficient for sparse address spaces
- A correct program should never address gaps
- If it does, trap to kernel and dump core
- When is it OK to address outside valid range?
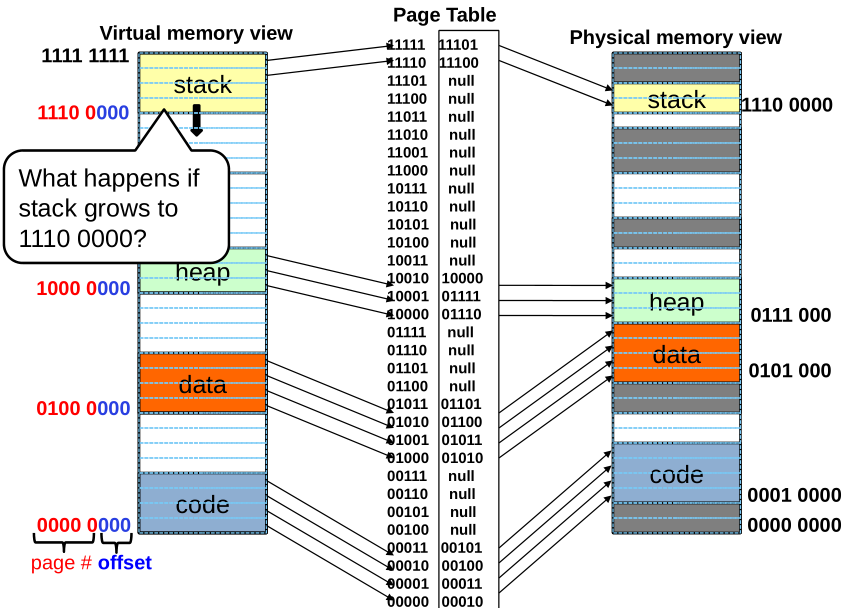
- This is how the stack and heap are allowed to grow
- For instance, stack takes fault, system automatically increases size of stack
- Need protection mode in segment table
- For example, code segment would be read-only
- Data and stack would be read-write (stores allowed)
- Shared segment could be read-only or read-write
- What must be saved/restored on context switch?
- Segment table stored in CPU, not in memory (small)
- Might store all of processes memory onto disk when switched (called “swapping”)
Problems with Segmentation
- Must fit variable-sized chunks into physical memory
- May move processes multiple times to fit everything
- Fragmentation: wasted space
- External: free gaps between allocated chunks
- Internal: do not need all memory within allocated chunks
General Address Translation
Paging: Physical Memory in Fixed Size Chunks
- Solution to fragmentation from segments?
- Allocate physical memory in fixed size chunks (“pages”)
- Every chunk of physical memory is equivalent
- Can use simple vector of bits to handle allocation:
- 00110001110001101 … 110010
- Each bit represents page of physical memory
- 1 -> allocated, 0 -> free
- Can use simple vector of bits to handle allocation:
- Should pages be as big as our previous segments?
- No: Can lead to lots of internal fragmentation
- Typically have small pages (1K-16K)
- Consequently: need multiple pages per segment
- No: Can lead to lots of internal fragmentation
How to Implement Paging?
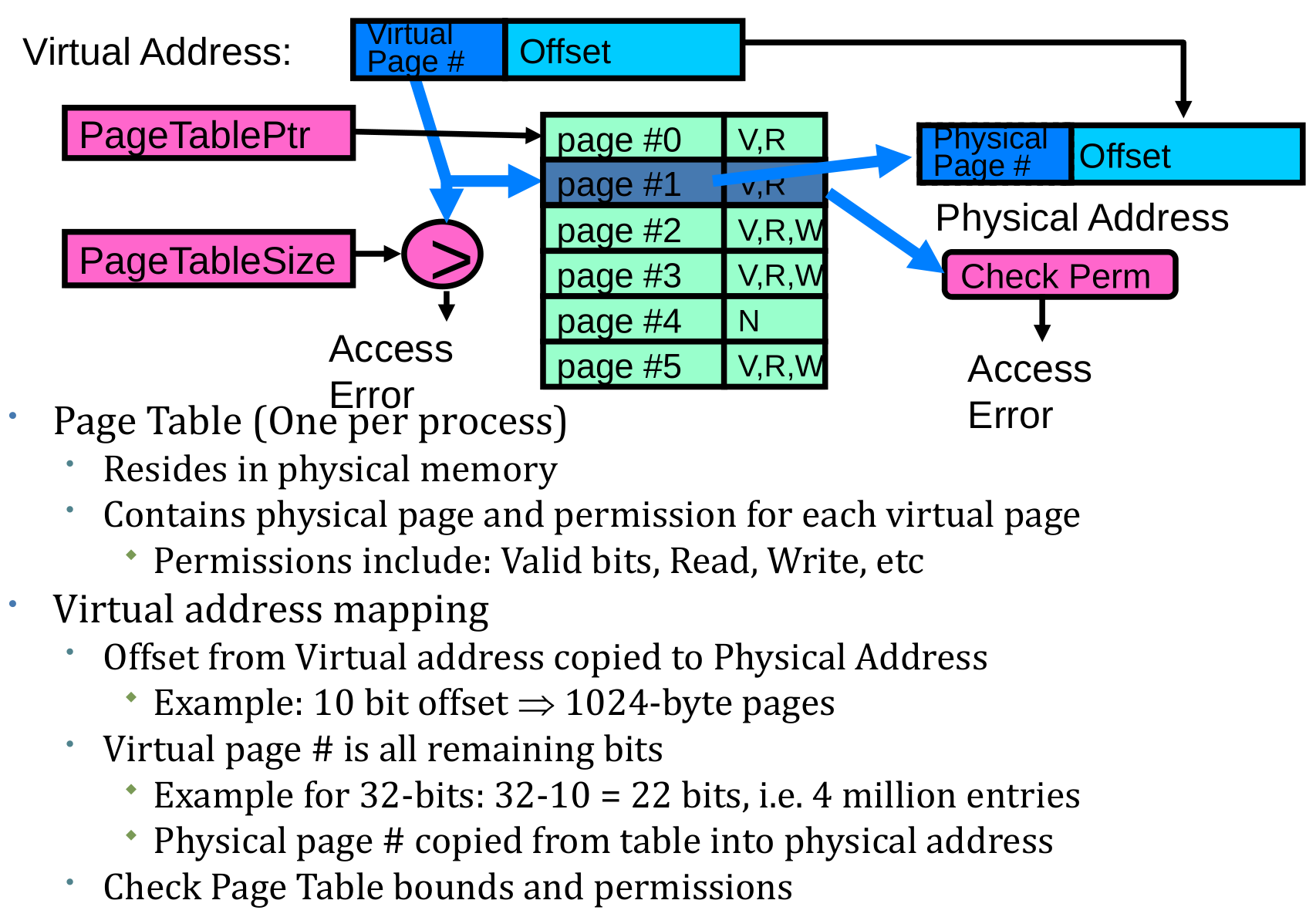
Simple Page Table Example
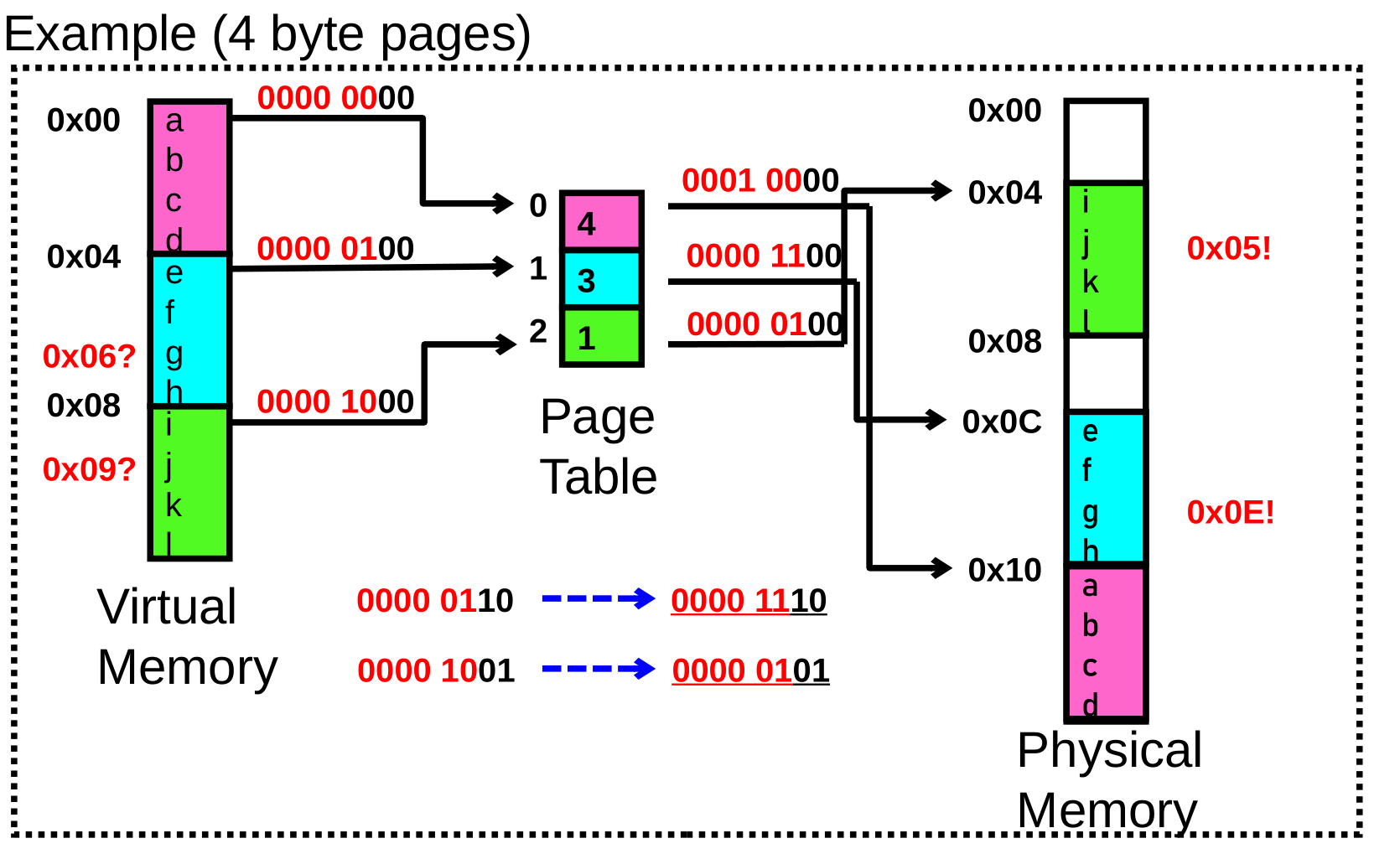
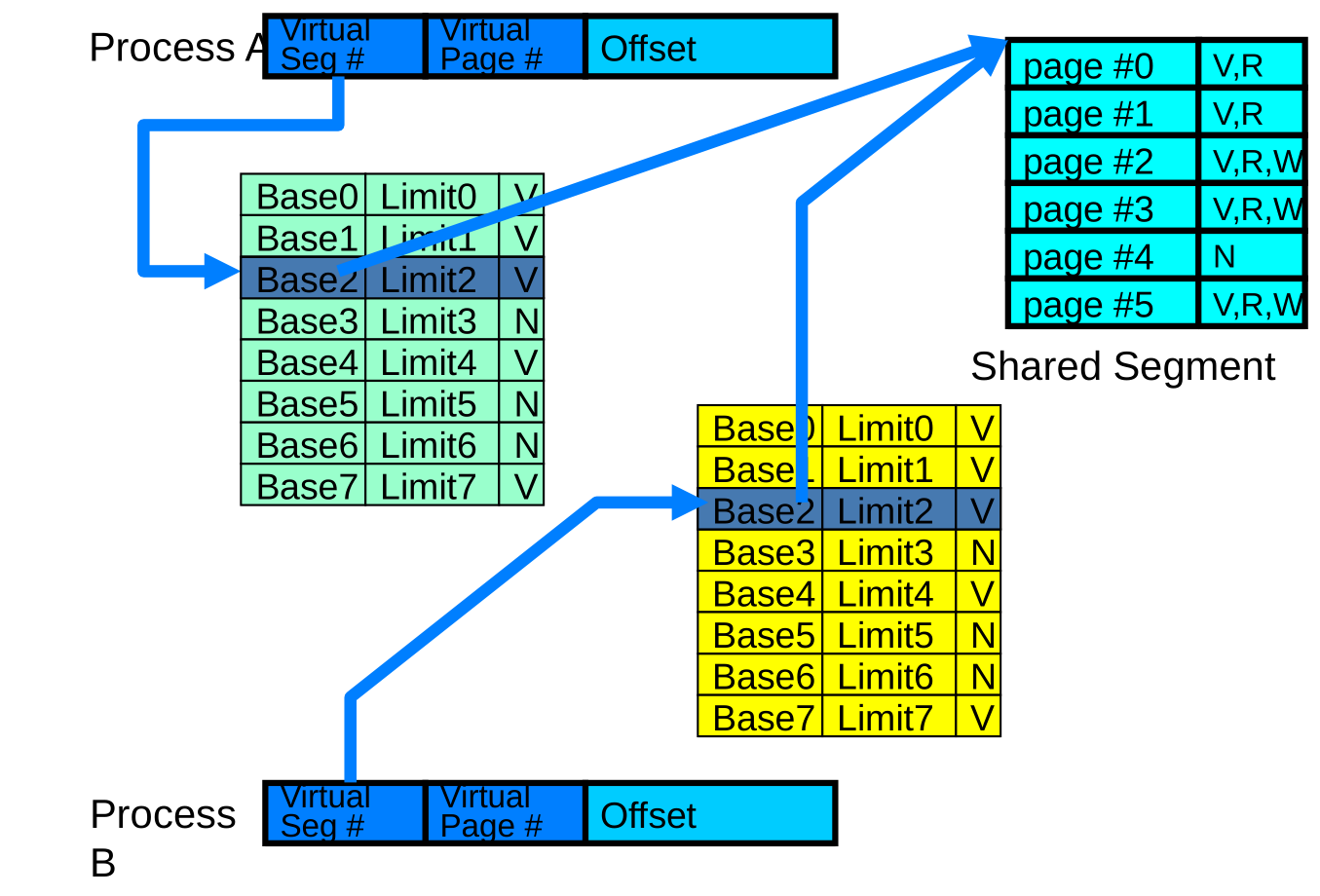
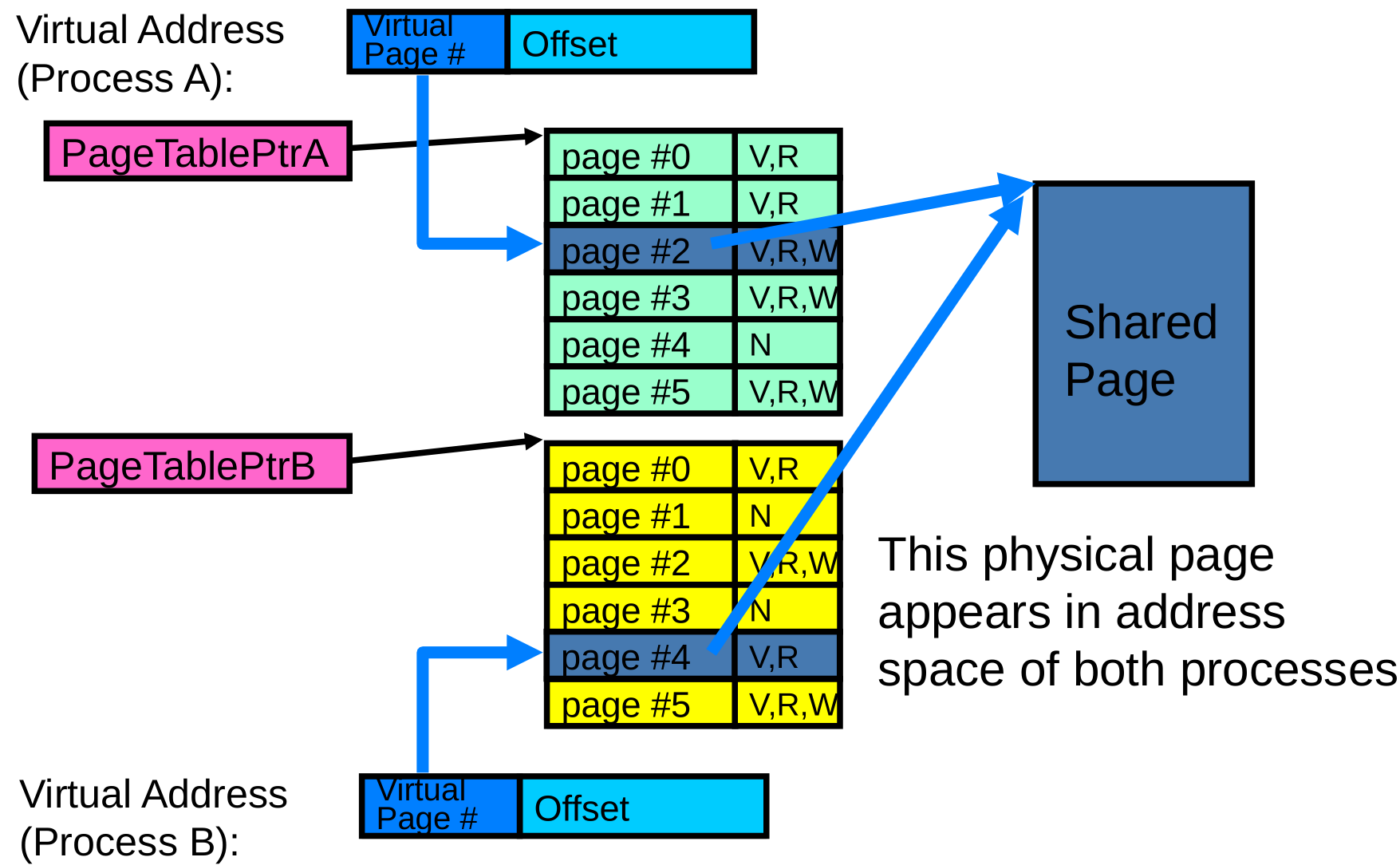
What about Sharing?
Summary: paging
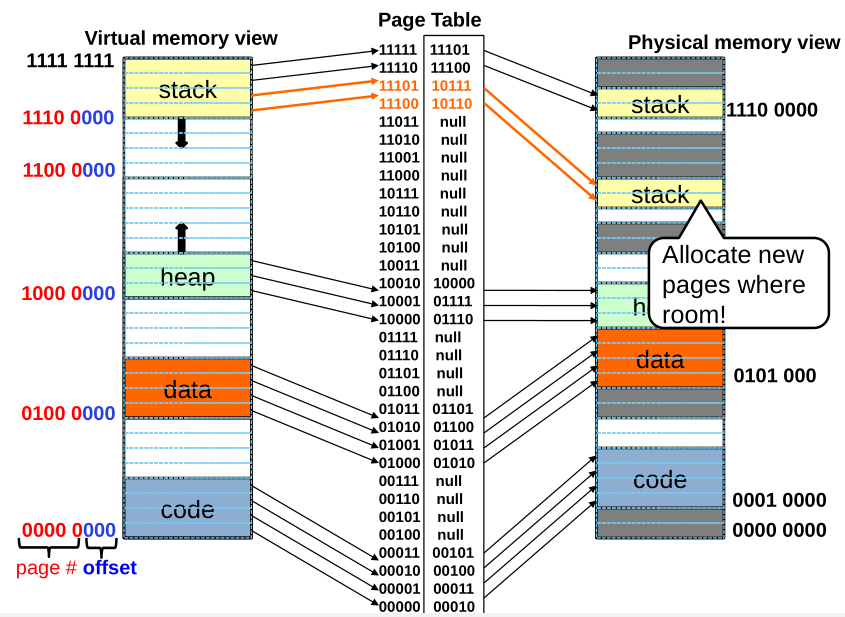
Page Table Discussion
- What needs to be switched on a context switch?
- Page table pointer and limit
- Analysis
- Pros
- Simple memory allocation
- Easy to share
- Con: What if address space is sparse?
- E.g., on UNIX, code starts at 0, stack starts at (231-1)
- With 1K pages, need 2 million page table entries!
- Con: What if table really big?
- Not all pages used all the time -> would be nice to have working set of page table in memory
- Pros
- How about multi-level paging or combining paging and segmentation?
Fix for sparse address space: The two-level page table
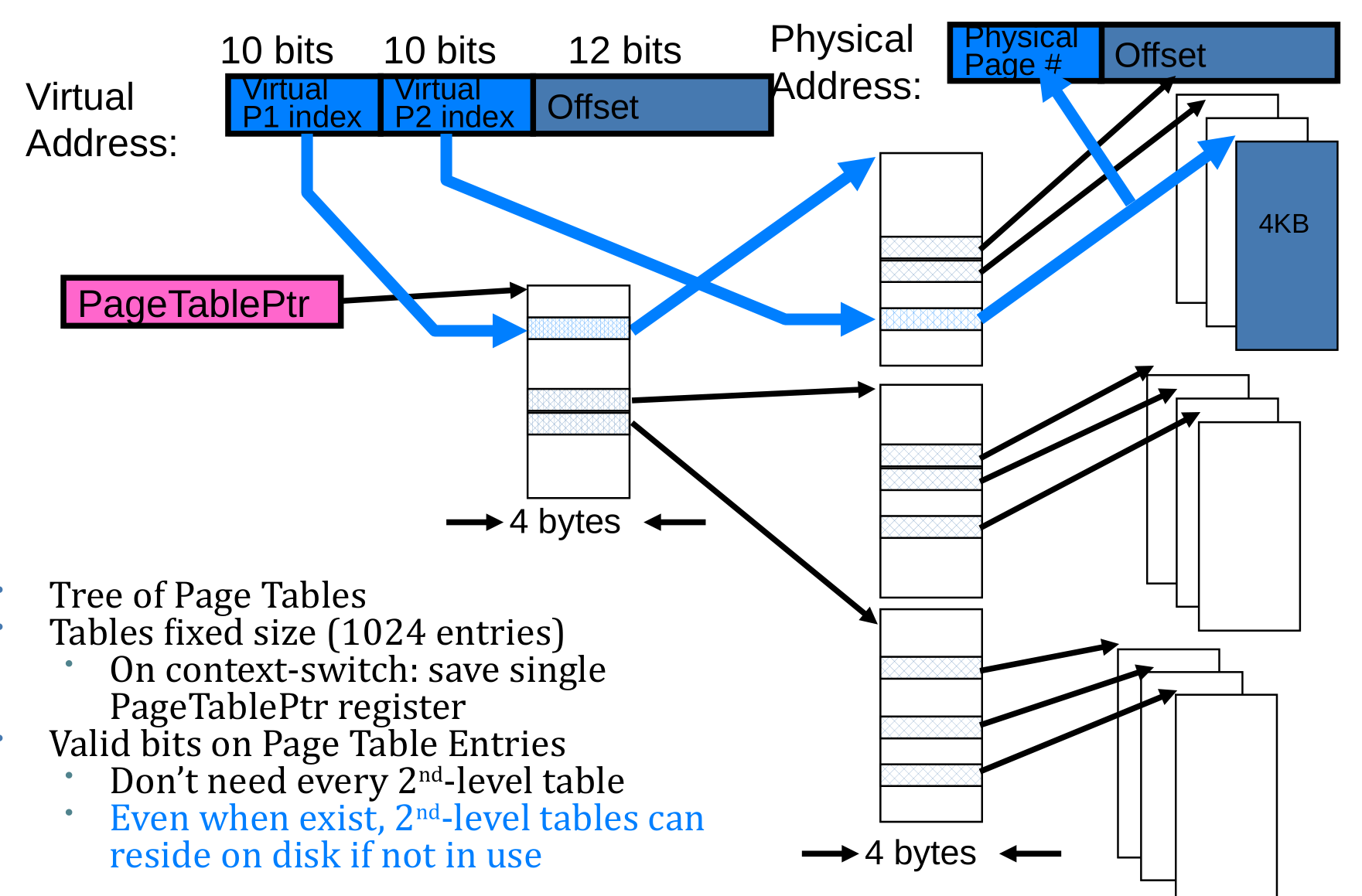
Summary: Two-Level Paging
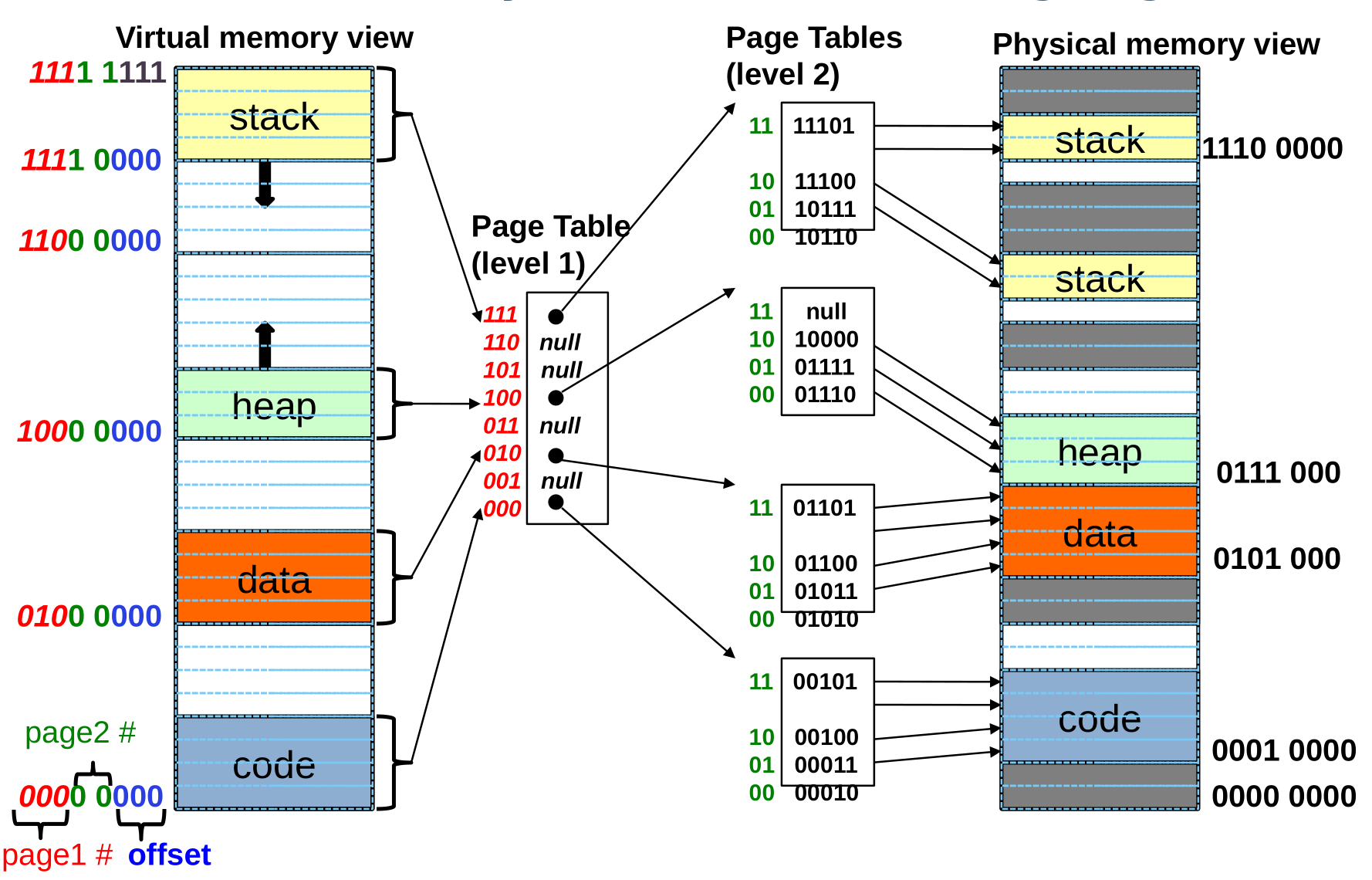
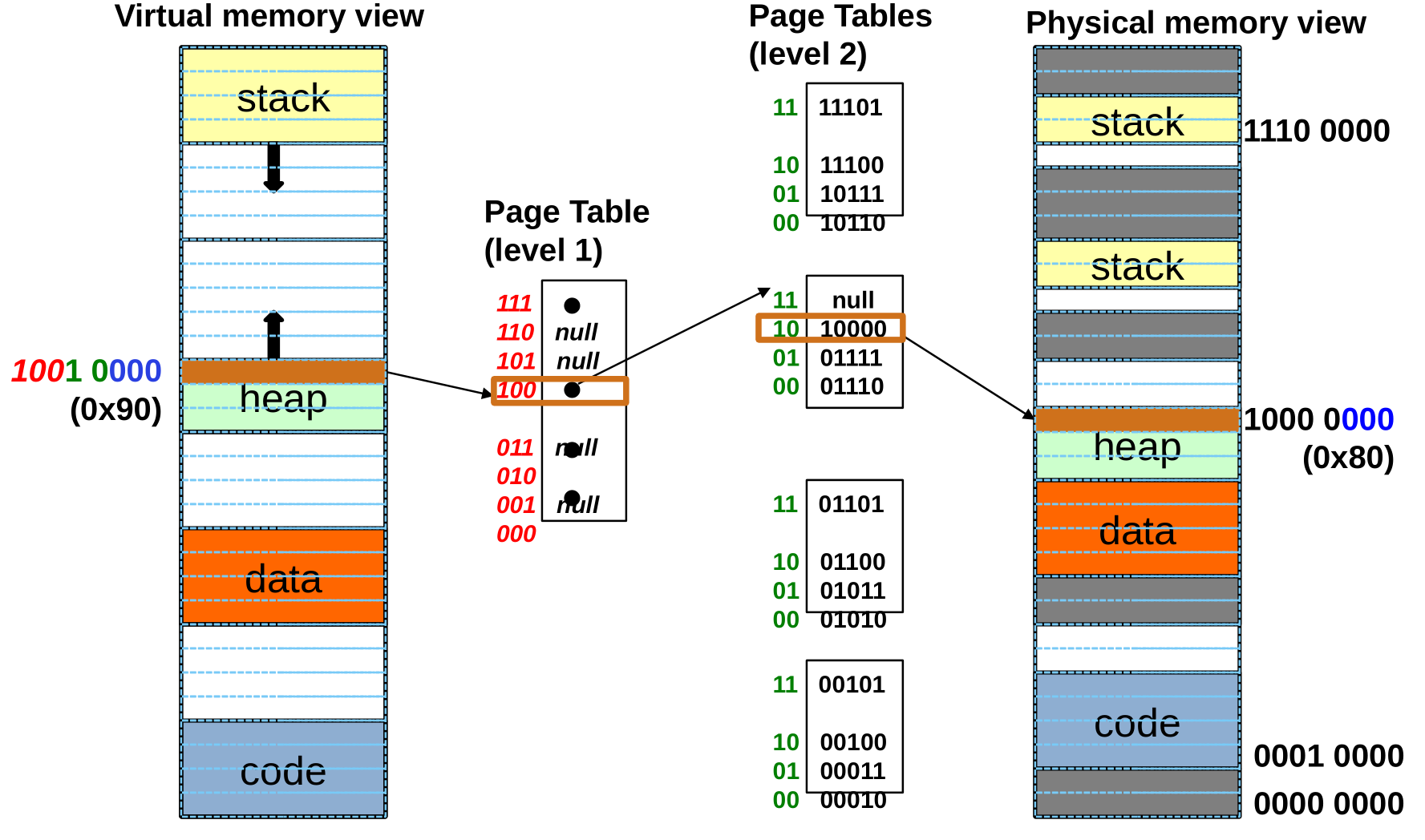
Multi-level Translation: Segments + Pages
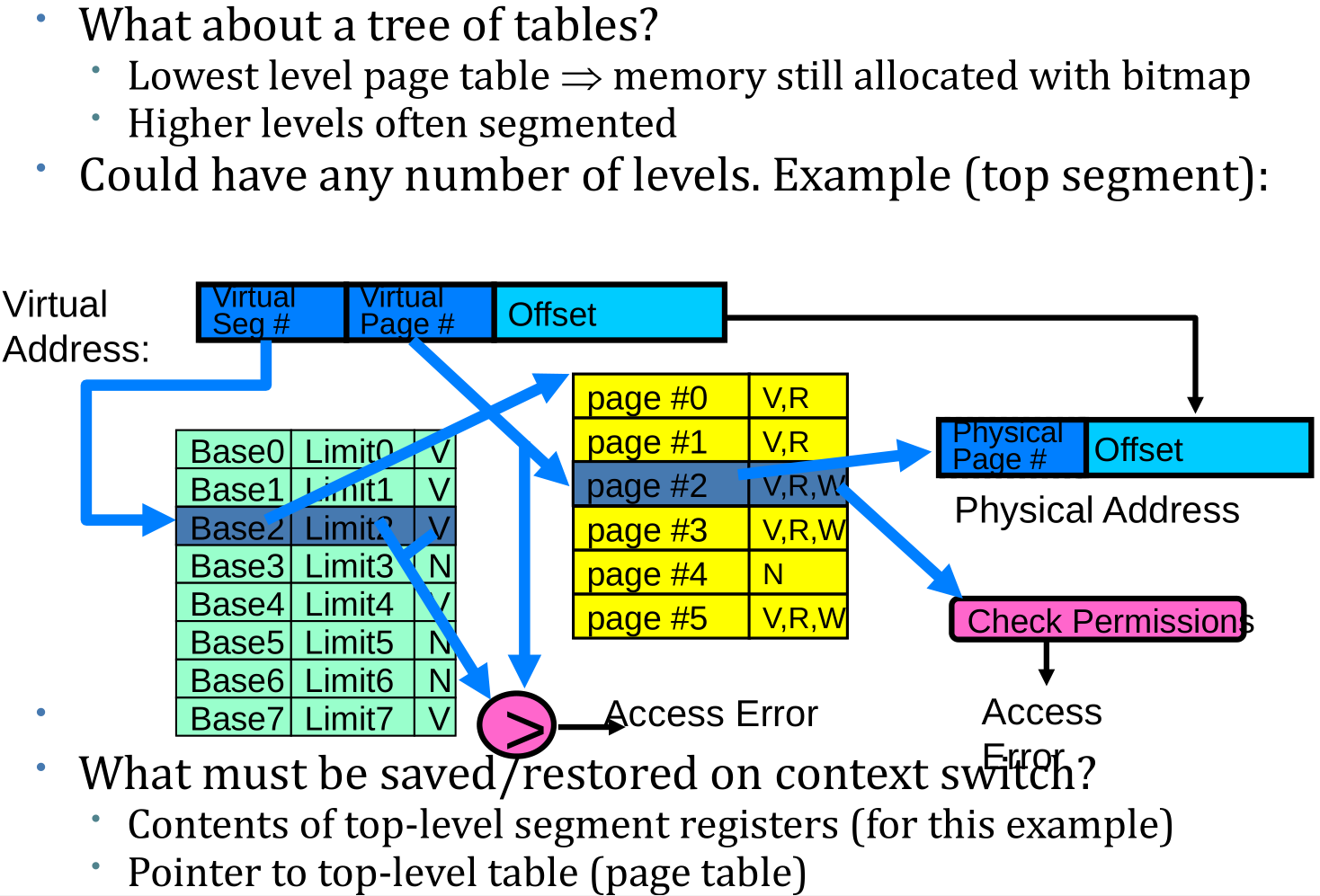
What about Sharing (Complete Segment)?