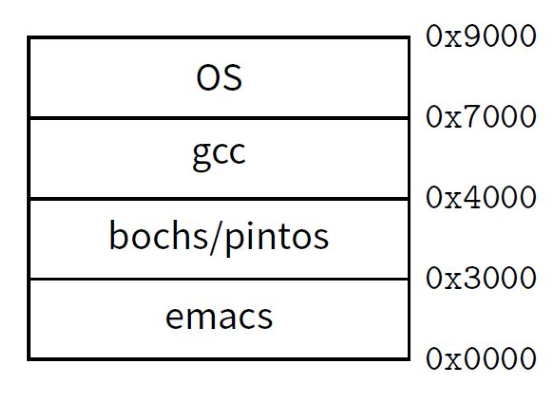
现在我成功的将手机上的APP数量降到了27个,其中包含了原生APP。这些APP有3个在dock栏中,另外24个则刚好占满iPhone 8 plus 的一页。
我想谈谈我在这个过程中遇到的一些困难和思路,也许能够给和我有着相同目标的极简主义者一些启发。
无疑的,我曾经是一个重度的移动互联网用户。如果按照十年前的标准,我想,现在绝大多数人都可以被称作是重度的移动互联网用户。我的手机也曾被各式各样的APP占满。在最开始接触到极简主义的思想时,我曾统计过我的APP总数,那时我手机中有150个APP。而如今,在接触极简主义的一年多后,我成功将这个数字降低到了27。除去Apple的原生app外,在手机上,我总共使用了其他互联网服务商的总计8个APP。
在最初接触极简主义之后,我首先将这个数量降低到了60多。这一步非常的容易,因为我很轻松的就找到了那些我三个月以上未曾打开的APP,并且将他们全部删掉。但在这之后的APP,才是极简路上的真正的大难题。
在逐渐极简掉剩下的APP的过程中,我的许多思维发生了很大的改变。
审视互联网服务商的开放性
自人类进入移动互联网时代以来,总体来说,互联网走向更加狭隘,封闭的地步。作为用户的我们似乎总是认为所有服务都应该有它自己的APP,而我们却忘记了互联网本质上是基于PC和Web服务这两个事实。但是实际上,所有你可以用手机做的事情,你都可以用PC更快更好的完成。基于互联网开放和自由的原则,我仔细审视了那些故意封闭自己服务圈的互联网服务,在这里我给出几个例子。
我不会使用知乎APP,知乎作为一个问答社区的所有功能和内容本可以在移动端的Web页面完成,但是它为了所谓的日活,KPI以及广告投放数据,在移动端的Web页面强制引导你下载它的APP。在APP中,如果你不登陆你就没法浏览它的内容。我是一个不在知乎上做内容产出和社交互动的用户,但即使如此我也必须登录才能使用。除此之外,你不得不忍受骚扰推送,不得不忍受夹杂在答案中的广告,不得不忍受那些把圈钱写在脸上的二级页面甚至是一级页面。但是我无法完全放弃知乎,因为它现在依然是中文互联网最优质的内容社区。因此,我转向于Web端的知乎。在浏览器上,我可以管控属于我自己的Web页面。我可以用基于JS的插件直接屏蔽掉它的广告,我可以随意的使用URL分享内容,我可以找到/explore这个未被服务商意识到的免登录使用的页面,或是直接使用插件屏蔽登录检测。在浏览器上,用户要自由得许多,而这些我在APP上被服务商故意限制和禁止的行为,本就是互联网赋予我们的基本的权利。
不使用APP的另一个好处是,它限制了我无时无刻沉迷在知乎的社区内容中。我不再会向从前一样从早到晚的被信息流干扰,只有在坐在PC前学习或工作时,我才会搜索我所需要的信息。如果不得已需要用手机使用知乎时,可以暂时的请求PC端的/explore的页面来查找信息。
我也不会使用支付宝APP和淘宝APP。作为一个互联网自由和开放的忠实拥趸,我旗帜鲜明的反对移动支付。因为无法接受我的交易情况可以被除了商家和我之外的另一个人知晓,也无法接受我的余额可以被其他人监管和冻结(你的现金无法被冻结,而银行卡被冻结的难度要比支付宝高上许多)。现金交易的匿名性无法被取代,在现实中可以使用现金的场景我绝不会使用移动支付。我曾经也使用支付宝购买基金,或是使用花呗分期付款,但现在我一律不用它额外的金融服务。我只用它来转账和在淘宝购物。
因此,我的一个原则就是:能够通过浏览器使用的服务,就不要通过APP来使用。基于这个原则,我卸载了很多的APP:知乎,淘宝,支付宝,豆瓣,百度网盘,百度等等
重新思考智能手机这件工具的用途
智能手机变得越来越强大,在很多事情上,智能手机表现得和PC端一样出色。比如说收发邮件,使用IM软件即时通讯,购物,刷微博等等。但是,智能手机破坏了不同事务之间的边界。工作,学习,娱乐之间不再泾渭分明。在十五年前,我们只能在电脑上使用QQ,如果要和人交流,我们必须打开电脑登录QQ。但是现在,我们每时每刻都登陆着QQ和微信,每天的上线时间是24个小时。智能手机消除了这种中断感----人们可以永远都在线,而不是像从前一样在特定的时间上线,在特定的时间下线。
这是我拒绝使用智能手机做太多事情的另一个原因,因为它实在是太强大了,随时随地都可以完成任务,比起PC来也毫不逊色。但是我的时间不再是整块的了。上一分钟可以在收发邮件,下一分钟就刷起了朋友圈。这种对于边界的消融让我感到害怕,因此我极简掉了许多的工具型的APP。我强迫自己使用专门的工具来做这些事情,给自己留出专注做事的时间。
比如说我卸载了GuitarTuna,转而使用实体的节拍器和调音器来练习乐器;我卸载了OneDrive,这样我只能在PC上进行学习(我的学习材料都在这里面);我也卸载掉了Documents和PDF experts,以及Microsoft的御三家,因为我不想在手机上查看,编辑,管理文件。卸载掉许多的APP,让我在时间上重新找回了边界感。简而言之,我不希望用智能手机做太多的事,哪怕它能做,而且也做得很好。如果能用一件工具完成某件事情,那我就不会保留多件相同用途的不同工具。
关于音乐
音乐是我生活中很重要的一部分,对大多数年轻的中国人来说,手机里必然会有一款音乐软件,甚至更多。我从15年开始使用网易云音乐,辅助使用QQ音乐,虾米音乐等其他软件。直到19年放弃它。最初我无比喜欢网易云的音乐+评论社区的设计,那会儿它也没有什么广告,我在上面建立了我整套的个人听歌体系。但后来,我发现它的曲库越来越少,越来越多的歌慢慢的灰了下去。有的时候甚至不给你提示,某首歌直接消失在你的歌单之中,直到你意识到你很久没有听到某一首歌了。软件里的广告和视频流多了起来,音乐页面被弱化成次要页面。更为过分的是,对于网易云没有的音乐,它会扫描识别出你手机中的对应的音乐,并且将它删掉,哪怕你是从其他的地方下载了这些音乐的文件。随后,网易云在某些歌上加入了经过aes加密的ncm格式,在从网易云下载音乐源文件时增加了一道不低的门槛。而我最终放弃网易云的导火索事件发生在19年的暑假,那会儿我在美国,惊诧的发现,由于地区版权保护,网易云中几乎所有的歌都变成了灰色。
在那之后,我仔细思考了音乐流媒体服务对于用户的意义。从前的我是一个自诩保护版权的人,我同时拥有三个音乐软件的年度会员(网易云,QQ,虾米)。但随后我发现,作为支持正版的付费用户的我得到的听歌体验甚至不如十几年前的盗版用户,没有会员,不再给资本家交钱的我甚至失去了听歌权。
我一直相信,互联网应该是自由的。互联网给了我不付钱自由听歌的权利。但是资本用所谓的版权意识教化人们放弃这种基本的权利。了解到版权之恶后,我才知道现行畸形的版权制度成了资本家敛财的工具,而没能真正的保护创作人,也没能给用户带来良好的体验。在这之后,我停用了所有的音乐服务,转向Apple Music 和 iTunes。Apple Music的曲库覆盖了我原有的音乐库。对于那些没法覆盖的歌曲,我会在国内软件中下载源文件(flac,ncm),然后将它转码成m4a导入iCloud资料库。至此,我才发现,每个月只用花5块钱就能带给我比同时使用三家音乐软件的会员更好的听歌体验。我的音乐完全属于我自己,我可以自己随意上传,修饰,描述它,不用担心它突然变灰或是被消失。而只保留一个音乐软件也符合极简主义的理念。同时,Apple Music中不存在censorship,我在iCloud中的某些歌不会像在网易云音乐云盘中被禁止收听。如果你想在多设备上同步音乐收听,同时也需要听一些利维坦不希望你听的歌(南京市民的歌,或是来自南方某座城市的一些歌,抑或《 Les Misérables 》中传唱度极高的主题曲),那么Apple Music和iCloud资料库应该是在中国最好的解决方案了。
关于IM软件,微信,QQ
如果你的手机中不存在微信,你在中国寸步难行。
在中国,你没办法逃避企鹅公司,一个中国人从出生到死亡的每一天都会收到企鹅公司的影响(尽管它的已知寿命还没有那么长),正如韩国人永远避不开三星公司一般。
在微信上,我取消关注了所有的公众号。其一出于我对其封闭内容生态的抗拒,其二出于我对这种“将信息送到我面前来”的信息推送方式的抗拒,其三出于我对内容本身的抗拒。第一点我在前面已经谈过许多了。企鹅至今没有完全开放过微信文章这个巨大的内容池的搜索接口,只为它的合作伙伴搜狗提供了一个搜索入口(和知乎如出一辙)。除此之外,你只能使用app内部的搜索入口,而这个搜索功能的体验如何自不比我多说。还可以谈谈微信的评论功能,作为一个内容发布平台,微信公众号在设计上就不存在让读者讨论的功能。文章底部的讨论最多只能做到个人留言以及作者本人的回复。我实在是无法理解这种功能残缺又封闭的平台如何就成为了中国最大的互联网内容池之一。
关于其二,我厌恶这种将信息摆在我眼前强迫我过目的方式。当我需一些内容时,我希望由我自己去搜索和比较,而不是在我不需要内容的时候有人将它放在我眼前。
我想这也是极简主义的一种体现:关注自己需要什么,而不是别人觉得我需要什么。
而第三点,微信文章这一形式本身并不适合作为工具类信息的载体,它与我信奉的实用主义并不相符。当一篇文章作为微信文章发布时,它必然背负了涨粉,流量转化,增加用户粘度,或是直接盈利的功能。在这种功利性的内容载体的影响下,文章本身的内容必然会受到影响。有多少次我们可以看到关注公众号领取,关注公众号获取密码,阅读原文查看原内容。这种模式强制性的将本可以开放的工具性信息转为封闭,强迫和诱导你在它的平台上进行内容消费和获取。文章本身也被强力的限制在微信这一载体中传播。这些形式会潜在而强力的影响文章内容本身。
我完全关闭了朋友圈功能,隐藏了所有的朋友圈,同时不再查看他人的朋友圈。当我意识到中国人群体性的社交模式的改变是一种社会学意义上的巨大变革时,已经是我开始使用朋友圈功能的五年后了。人们的社交思维和理念被一些代码改变,作为深刻影响人类的发明,朋友圈是成功的。你必须思考朋友圈礼仪,思考每个点赞带来的后果,思考评论的时机和意义,思考他的朋友圈所隐含的信息,思考每条朋友圈带来的潜在人际关系影响,思考朋友圈内容对个人形象的塑造作用。中国人头脑中的社交思维已经发生了剧烈的改变。
想清楚这些事实之后,我便发现我完全没法接受它们。我不能忍受一个互联网公司在一个app中推出的一个二级页面,就成为了在中国社会除学识,修养,谈吐,智商这些禀赋之外的另一种评判人的维度。我不能忍受一个互联网公司把持我人际交往中的重要部分,它应该只是社交内容传达的载体和工具,而不应该反过来影响我的社交内容本身。我不能容忍所有人都在朋友圈中评判与被评判,就像《黑镜》中的某集,所有人一辈子都在评分和被评分。弄明白这些事情之后,我能够坚决果断的跳出这个圈子。
我拒绝使用微信小程序以及微信支付。后者我也已经说明过,前者是站在作为开发者的我的角度思考而得出的结论。作为开发者,我非常讨厌微信的立志于做操作系统的态度。在对工具的使用上,我奉行Unix系统“小即是美”的哲学。一件工具应该专注于做好它本被赋予的任务,而不应该越俎代庖做操作系统或是其他软件该做的事情(这是国内的互联网公司的通病)。音乐软件只应该用来听歌,而不应该用来进行短视频流内容消费或是进行实体购物。同样的,IM软件应该只用来传递和交流信息,而不是应该去做支付软件或是小程序平台。
我删除了所有的微信表情包。在已经切断了微信的这么多功能之后,做到这一点条轻而易举。表情包在改变人类的交流模式上也是成功的发明。但表情包将本可以严肃的内容交流娱乐化,降低了人们交流的严肃性,也在一定程度上阉割了人类的语言表达能力。我会轻微的抵触表情包。
关于QQ,我的做法大致与微信相同,不再赘述。
最终,我让我的微信和QQ成为了一个部分契合我理想的IM软件。在一定程度上我做到了极简,它们本就只应该用来交流和传递信息,而不是用来做其他不是它们分内的事情。我只用它们做本应该做的事情,仅此而已。
做同样的事情,我们需要多少工具
智能手机是一件强大的工具,我们可以用它做很多事情。很多原本需要由不同工具来完成的任务现在都可以用手机来完成。你不再需要随身音乐播放器,车载导航系统,或是如我前文所述的调音器和节拍器。但是定下心来想想,手机太强大了,但是我们需要这么强大的它吗?我们真的需要手机厂商宣传的无缝工作功能,让我们可以在电脑和手机之间同步工作内容吗?我们真的需要每一台设备上都有Kindle的APP,PC上有Kindle的桌面软件,以及还拥有一部实体的Kindle吗?玩《集合啦!动物森友会》时我们一定要用手机APP来查看小动物们的状态或是和朋友聊天吗?电脑上登录了QQ,手机上也要一直登陆着吗?电脑上可以看bilibili,手机上也需要保留bilibili的APP吗?能用一件工具解决的问题,就不用两件工具解决,我想这也是极简主义的原则。极简主义会要求我只保留一个我最喜爱的杯子用来喝水,而不是同时有三四个好看而且都不忍割舍的杯子。现在这件事情只是转移到了小小的屏幕上,主体对象也不再是杯子,变成了互联网服务。
这样,我们可以轻而易举的把对待实体物品的态度转移到对待虚拟物品上来。既然我只保留一个水杯或是一个台灯或一支笔,那我就没有必要保留多个Kindle的APP或是Word,Powerpoint和Excel。我可以用iPad和PC来查看学习笔记或者读论文,我就不会用手机去学习。Web端的淘宝也可以购物,我就没必要留下淘宝APP。公交卡可以乘车,为何我一定要下载APP呢?我们需要弱化手机的功能。那些用其他工具完成得更好的事情,就不要用手机来做。我只用手机做那些只有手机能做,或是手机做得比其他工具要好的事情。